
九游体育app官网跟着晶体管器件中庸金属互连之间的氧化膜越来越薄-九游体育「NineGame Sports」官方网站 登录入口
新闻
要说镶嵌式行业有多卷,想必工程师皆有体会。时候来到下半年,本年厂商依然在束缚"飙车",跋扈迭代。 接下来,EEWorld 就来盘货一下本年镶嵌式行业的技巧风向。 RISC-V MCU,快速崛起 华为海想近期发布了 Hi3066M 与 Hi3065P 两款 RISC-V 芯片:Hi3066M 是针对家电端侧智能化需求想象的镶嵌式 AI MCU,使用海想自有 RISC-V 内核,内置 eAI 引擎,援手 200MHz 主频、64KB SRAM 和 512KB 内置 Flash;Hi3065P 是针
详情

要说镶嵌式行业有多卷,想必工程师皆有体会。时候来到下半年,本年厂商依然在束缚"飙车",跋扈迭代。
接下来,EEWorld 就来盘货一下本年镶嵌式行业的技巧风向。
RISC-V MCU,快速崛起
华为海想近期发布了 Hi3066M 与 Hi3065P 两款 RISC-V 芯片:Hi3066M 是针对家电端侧智能化需求想象的镶嵌式 AI MCU,使用海想自有 RISC-V 内核,内置 eAI 引擎,援手 200MHz 主频、64KB SRAM 和 512KB 内置 Flash;Hi3065P 是针对家电、工业等限制想象的高性能、大存储实时贬抑 MCU,使用海想自有 RISC-V 内核,援手 200MHz 主频,援手 64KB SRAM 和最大 512KB 内置 Flash,可援手客户家具功能继续迭代和算法升级。
由此可见,RISC-V 照旧成为海想下一个计谋支点,"备胎策画"或已起程。近期海想还发布了一系列自研芯片,包括 Cat 1、ADC 等。
沁恒四肢 RISC-V 限制老玩家,一直被工程师所关怀,因为开发者较多,遇到问题也可以快速惩处,同期"青稞 RISC-V+ 接口 PHY "全栈研发方式在鼓舞 RISC-V 运用落地上具备原生上风。
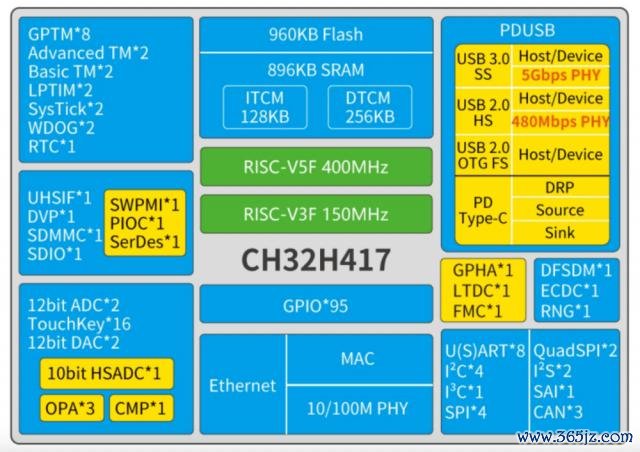
最近,沁恒的双核 RISC-V MCU CH32H417 是其主推家具。CH32H417 基于青稞 RISC-V5F 和 RISC-V3F 双内核想象的互联型通用微贬抑器,集成 USB 3.2 Gen1 贬抑器和收发器、百兆以太网 MAC 及 PHY、SerDes 高速讳饰收发器、Type-C/PD 贬抑器及 PHY。
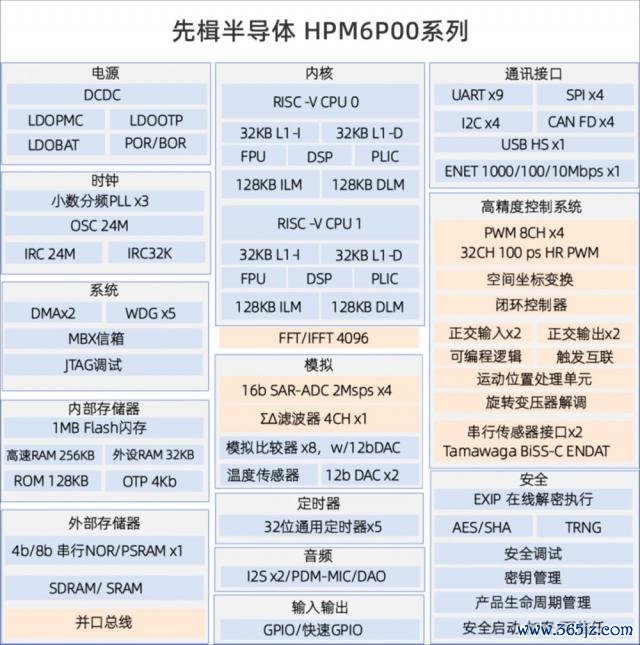
先楫的 RISC-V MCU 在国内口碑罕见可以,这家公司最近主推家具是高性能家具 HPM6P00。该系列旗舰家具 HPM6P81 内置 RISC-V 双核,主频达到了惊东说念主的 600 MHz,援手多达 32 路高分裂率 PWM 输出,配备 4 个沉寂 16 位 ADC 和 8 个高速模拟比较器,并集成 Σ ∆数字滤波、硬件电流环等高精度通顺贬抑模块,昂扬严苛贬抑运用需求。
RISC-V MCU 上车,亦然近期关怀的热门。此前,英飞凌晓示将引颈汽车行业弃取 RISC-V,策画改日几年推出基于该架构的全新汽车微贬抑器系列。该系列将纳入其熟谙的 AURIX 汽车微贬抑器品牌,以彭胀现存基于 TriCore 和 Arm 的家具组合,粉饰从初学级到高性能的平素汽车运用,边界特出刻下市集现存家具。此外,英飞凌四肢 RISC-V 方法化的首要鼓舞者,正积极布局 RISC-V 在汽车限制的运用与生态开荒。
EEWorld 得知,ST 面前也在不雅望 RISC-V 在 MCU 中的契机,有有关策画的话会实时向市集清楚有关的信息。此外,ST 也在不雅望在中邦腹地坐蓐汽车 MCU 的契机,40nm 在中国坐蓐技巧上整个可行,ST 不摒除这么的可能性。
汽车 MCU,开启存储改换
对汽车 MCU 来说,eNVM 至关首要,它用于存储车辆的要道代码和首要建树数据。不外 eFlash 局限也很阐述,比如,可重写次数太少,跟着每次写入和擦除周期,浮栅 NOR 单元中地说念氧化物会退化,走电会增多,从而加快 eFlash 老化。
更首要的是,eFlash 基本锁死了 MCU 制程迭代的路。因为 eFlas 晶体管构造极度,28nm 以下 eFlash 需要的掩摸层数太多,很难完结微缩化。加之 eFlash 高出 40nm 可靠性会受到存储单元、外围晶体管、金属互连适度,跟着晶体管器件中庸金属互连之间的氧化膜越来越薄,瞬态介电击穿寿命严重下落。
为了搪塞上述挑战,如今汽车 MCU 启动运用下一代 eNVM 技巧。其平分为三条道路——包括相变存储器、阻变存储器和磁阻存储器。
PCM:ST 最近推出内置 xMemory 的 Stellar 系列汽车 MCU,其 PCM 基于 28nm 与 18nm FD-SOI 工艺,其存储密度可达竞品两倍以上。
意法半导体汽车 MCU 处事部高档总监、处事部计谋办公室成员向 EEWorld 阐述,PCM 的上风包括五点:1.PCM 提供同类最小存储单元,可在尽可能小单元面积完结以往一倍以上的信息存储信息量耕作;2.PCM 可在不修订资本情况下,将举座存储容量耕作一倍;3. 领有雄伟耐高柔顺耐发射性能,以致可在 165 ℃结温之下踏实运行;4. 能在恶劣工况之下也保持较低功耗;5.PCM 非新技巧,从二十年前于今技巧熟谙度照旧罕见高,ST 照旧接洽 PCM 多年,因此罕见安全可靠。

MRAM:NXP 最近推出了公共首款 16nm FinFET+MRAM MCU S32K5,四肢一款区域贬抑器,它既可以集成通盘实时贬抑功能,也能用作区域团员器或网关。
恩智浦半导体资深副总裁兼汽车微贬抑器总司理 Manuel Alves 向 EEWorld 默示,MRAM 具备独到的上风,一是写入和编程速率极快,比闪存快 10 倍,可快速运行,二是永恒性强,能完结 100 万次写入,不仅可存代码,还能用于数据存储,天真性高,便于数据汇集和跨区域存储。
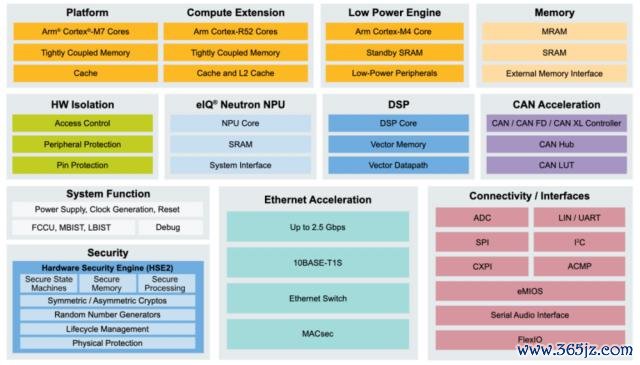
RRAM:Infineon 前年发布弃取台积电 28nm 的 AURIX TC4x 系列 MCU,并引入 RRAM。弃取新一代 TriCore 1.8 架构,主频达到 500MHz,搭载 PPU 并行处理单元。
Infineon 以为,与 NOR Flash 比拟,RRAM 驱动法子简单,其在重写内存之前不需要擦除敕令,同期还援手字节粒度写入,大大简化了驱动法子想象,更少的敕令和内存操作也有助于 RRAM 技巧固有的功率、性能和永恒性上风;与 EEPROM 比拟,RRAM 具有更快的写入速率和更高的密度,使其适用于需要不时更新数据的运用,举例数据纪录;与 MRAM 比拟,RRAM 的运行功率成果更高,提供了性能、功率和资本的平衡组合。
AI MCU,要卷疯了
跟着 AI 大模子发展,面前确实每家厂商皆会推出带有 NPU 的 MCU 家具,同期加大关于软件还有模子上的参预。
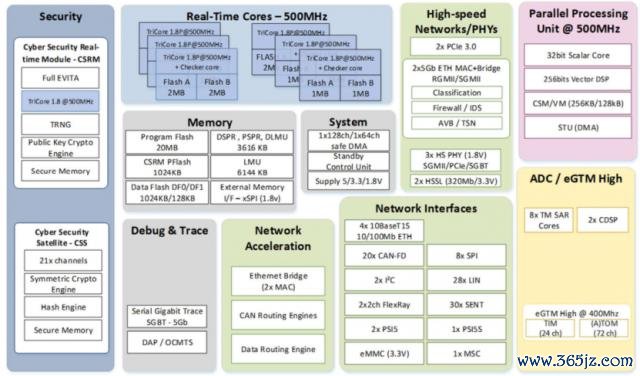
STM32 确实是每个工程师必会的家具之一,面前 ST 正在加大关于边际 AI 的硬件加快、优化软件栈、安全功能以及从边到云几大趋势的参预。
硬件上,STM32N6 是其主推家具,NPU 方面弃取自研 Neural-ART 加快器,频率达到 1GHz,算力达到 600 GOPS,平均性能 3 TOPS/W,而在 CPU 上,Arm Cortex-M55@800 MHz 引入 Arm Helium 向量处理技巧为方法 CPU 带来了数字信号处理;此外,ST 曾向 EEWorld 流露,策画在 Stellar P 和 G 的家具当中进一步集成 NPU 功能,并在而后公布注意的策画。
软件上,ST 提供 Edge AI-Core、Edge AI Developer Cloud、STM32Cube.AI、NanoEdge AI Studio、AI for OpenSTLinux、StellarStudioAI、AIoT Craft、MEMS Studio、MLC/ISPU 模子库等。
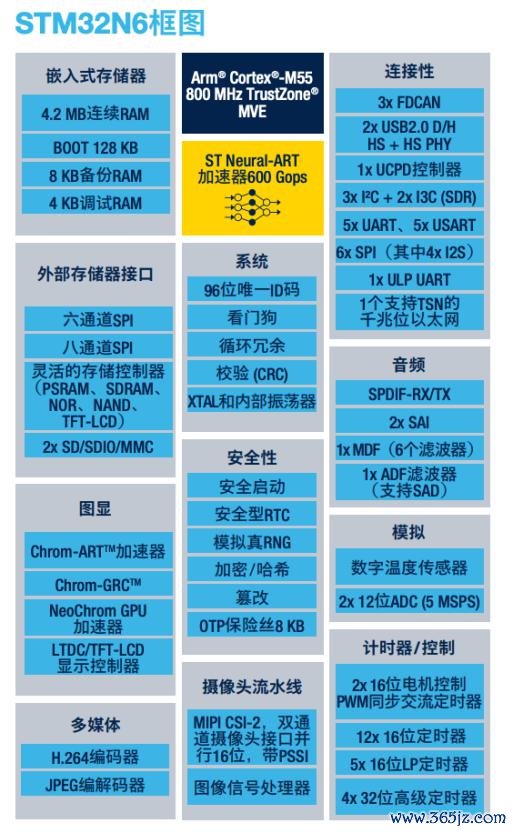
Infineon 在 2024 年登顶公共 MCU 榜首,在 AI 上的计谋亦然软硬件两手捏。
硬件上,英飞凌新式 PSOC Edge E8x MCU 系列想象成为首家达到镶嵌式安全框架 PSA4 最高认证条款的家具,通盘 PSOCTM Edge E8x 微贬抑器均采器具有安全启动、密钥存储和加密操作功能的片上硬件讳饰飞地。其中,PSOC Edge E83 和 E84 内置 Arm Ethos-U55 NPU 处理器,E81 则弃取 Arm Helium DSP 技巧和英飞凌 NNLite 神经汇集加快器。
软件上,Infineon 在 2023 年收购了 Imagimob,并于 2024 年推出边际 AI 软件惩处有策划品牌 DEEPCRAFTTM,其可与 ModusToolbox 一站式完成数据采集及预处理、模子本质、优化以及部署的全经过。英飞凌提供了多种开箱即用的模子,最新模子包括声源主义检测模子、名义检测模子、工场报警检测模子、手势检测模子、摔倒探伤模子等。

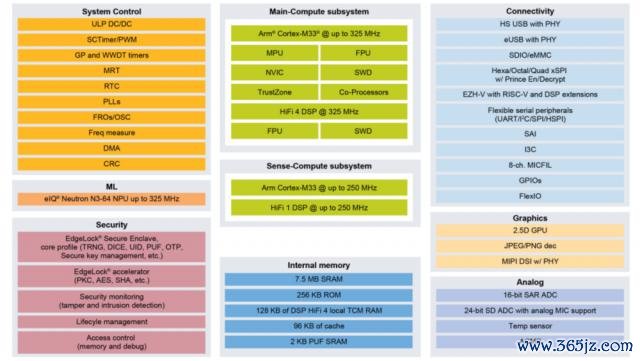
NXP 在端侧 AI 上的计谋所以高度集成硬件、软件和系统惩处有策划为中枢,强调功能安全、低功耗和可彭胀性。NXP 以为,Agentic AI 照旧来到了边际,自主边际是接下来行业发展的下一步。
这几年,NXP 越来越强调惩处有策划的见解,而很少说起单个家具,固然如斯,其家具升级幅度依然很大。NXP 的 eIQ Neutron NPU 照旧粉饰 MCU、跨界 MCU、运用处理器三大系列,尤其是其在前年底推出的跨界 MCU i.MX RT700,耕作幅度罕见之大,可以说是"降维打击"。比拟上一代家具,其在边际提供高达 172 倍的速率耕作和 119 倍的节能,同期功耗比上一代家具镌汰了 30~70%。i.MX 9 系列处理器也集成了 Neutron NPU,援手从基本推理到复杂的多模态 AI 运用,包括 eIQ AI 开发套件,用于优化 AI 模子的性能和成果。
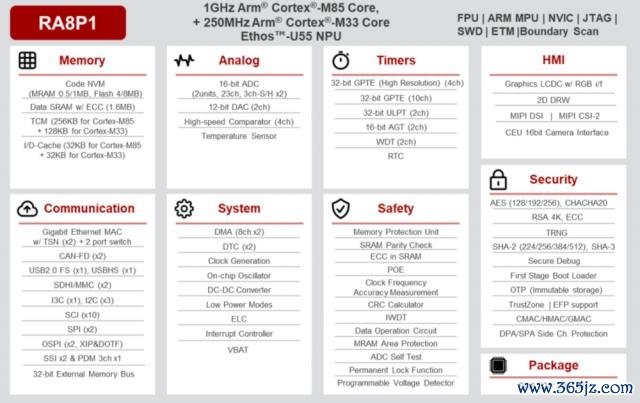
瑞萨这几年在 MCU 限制一直走得比较快,家具更新频率也很高,比如最初使用 M85、M55 之类的内核。在边际 AI MCU 上,最近性能极为雄伟的 RA8P1 启动肃穆发售,其将 1GHz Arm Cortex-M85 和 250MHz Cortex-M33 CPU 中枢、与 Arm Ethos-U55 NPU 相汇聚,完结了业界最高等第的 7,300 CoreMark CPU 性能以及 256 GOPS AI 运算性能。
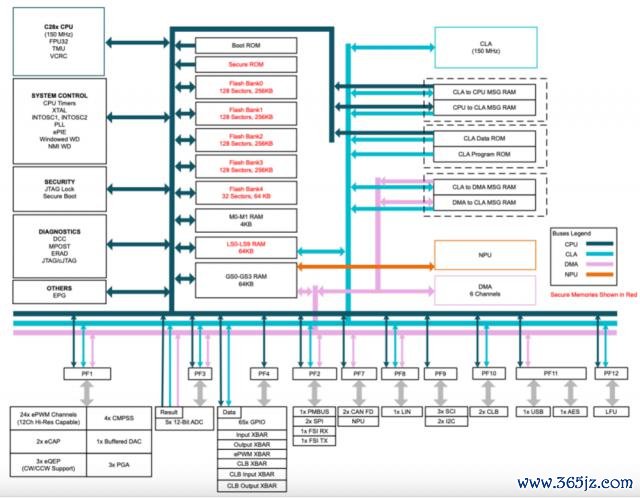
TI 的 C2000 四肢经典 MCU,也在束缚升级,前年年底,C2000 也终于启动拥抱 NPU ——发布 TMS320F28P55x 系列,可完结高精度和低蔓延的故障检测。F28P55x 实时内核弃取 C28x 系列的 32 位 150MHz DSP MCU,NPU 具有 600~1200MOPS 智商。通过 NPU,与软件完结比拟蔓延镌汰了 5~10 倍。此外,在集成 NPU 上运行的模子通过本质学习并适当不同环境,可以匡助系统完结高出 99% 的故障检测准确率,从而在边际作念出更贤达的决策。
ADI 在夙昔两年也很强调边际 AI 的见解。比如 MAX7800X 系列 MCU 由两个微贬抑器内核与卷积神经汇集加快器组成。最近,ADI 和 Antmicro 共同开发的 AutoML for Embedded,面前四肢 Kenning 框架的一部分提供,Kenning 框架是一个与硬件无关的开源平台,用于在边际开荒上优化、基准测试和部署 AI 模子。AutoML for Embedded 旨在让从镶嵌式工程师到数据科学家的每个东说念主皆可以侦查、高效和可彭胀边际 AI。
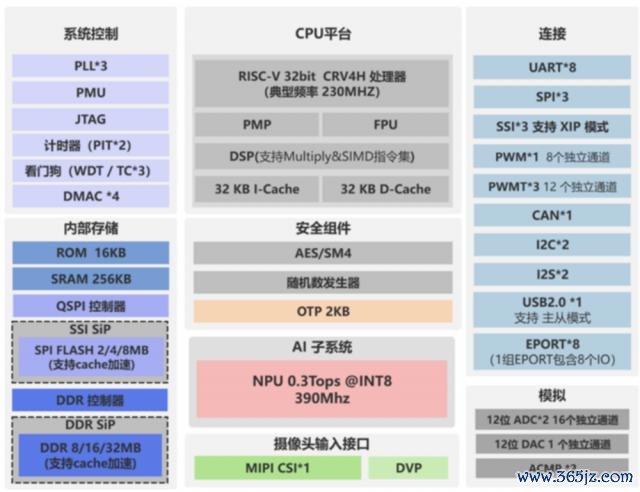
国芯科技推出基于 RISC-V 架构的端侧 AI MCU 芯片 CCR4001S 弃取公司自主开发的 RISC-V 内核 CRV4H,主频 230MHz,集成了一个 0.3 TOPS@INT8 算力的神经汇集处理单元,专诚用于加快 AI 任务。
存算一体,下一场改换
冯 · 诺依曼策画架构照旧许多年了,其正濒临"存储墙"和"功耗墙"两大瓶颈。新式存算一体芯片就被视为后摩尔期间冲破冯 · 诺依曼架构瓶颈的首要技巧主义之一。
这适值与 AI 期间 MCU 濒临的问题相易:"如安在严格贬抑功耗、资本与体积的情况下,集成充足的算力来昂扬边际 AI 推理需求?"
苹芯科技日前发布了一款基于存算一体的 NPU IP 核 PIMCHIP-N300,可竣工昂扬 MCU 级芯片对低功耗、低资本的需求,惩处传统 MCU 无法高效运行 AI 算法的勤劳。其弃取 SRAM 存内策画技巧,在 28nm 工艺下将策画中枢能效比耕作至 27.3 TOPS/W,而在 22nm 工艺下可完结 1~2mW 超低功耗待机,为智能穿着、AIoT 开荒提供了" Always Online "的 AI 智商。
此前,EEWorld 从一些厂商共享中得知,正在布局下一代具有存算一体技巧的 MCU 家具。
总之九游体育app官网,从面前存算一体芯片运用情况来看,委果能够为端侧 AI 带来功耗上的上风。要是将存算一体与 MCU 汇聚,不详让 MCU 既能运行高负载的 AI 算法,又能领有极低的功耗,同期为 MCU 厂商神圣了谨慎的芯单方面积资源,搪塞碎屑化、个性化场景。
